AI 大模型 / 生产力工具 2026年1月14日
OpenAI o3、o4 mini high 深度评测:谁才是数学推理与编程工程的真王者?
对比评测 OpenAI o3、o4 mini high 与 Gemini 2.0 Pro 在 LeetCode 算法、Web 工程开发和游戏 AI 策略等方面的实际表现。
#OpenAI
#o3
#o4 mini high
#Gemini 2.0 Pro
#编程评测
#数学推理

Quick Verdict
本次评测揭示了目前顶级推理模型的显著分化:o4 mini high 在纯数学算法和逻辑推理上展现了统治级优势(LeetCode 困难题 100% 一次通过),但在实际软件工程和复杂逻辑维护上却表现最差;o3 与 Gemini 2.0 Pro 在工程实践和游戏逻辑编写上更具优势。如果你追求极致推理,选 o4 mini high;追求工程辅助,o3 或免费的 Gemini 是更优选。
Key Decision Factors for AI Models
- 算法推理深度:模型处理 LeetCode 困难级别(Hard)问题的能力。
- 工程代码质量:生成可运行项目、处理外部依赖版本以及 UI 美观度的能力。
- 自我纠错能力:在面对报错反馈时,能否通过迭代真正修复 Bug 而非引入新 Bug。
- 性价比与额度:API 成本以及是否有慷慨的免费使用额度(如 Gemini)。
Specs & Benchmarks
| 评测维度 | Gemini 2.0 Pro | OpenAI o3 | OpenAI o4 mini high |
|---|---|---|---|
| LeetCode 困难题 (2道) | 通过 1 道 (第3次尝试) | 未通过 | 通过 2 道 (均为1次通过) |
| Markdown 转思维导图 | 勉强通过 (需人工修复版本) | 失败 (后期负优化,无法运行) | 失败 (包名/版本完全虚构) |
| Flappy Bird 基础开发 | 完美通过 | 完美通过 | 完美通过 |
| AI 自动玩游戏策略 | 优秀 (稳定得分策略) | 优秀 (稳定得分策略) | 失败 (计算策略持续失误) |
| 官方 Codeforces 分数 | 较高 (参考) | 极高 (参考) | 极高 (参考) |
The Ugly Truth
- o4 mini high 的”幻觉”硬伤 [00:14:10]:在工程测试中虚构了不存在的依赖版本(如
mindelixer 4.6.1),导致项目从根本上无法初始化。 - o3 的”负优化”现象 [00:12:53]:在进行代码迭代修复时,o3 容易引入更多新 Bug,甚至导致原本能运行的程序最终崩溃。
- Gemini 的 UI 审美与版本滞后 [00:06:19]:生成的界面极其简陋,且默认使用的第三方库(AntV G6)版本过旧,导致代码无法直接运行,需手动降级版本。
- 算法与工程的脱节 [00:22:15]:o4 mini high 虽然数学极强,但在处理游戏物理坐标计算和策略逻辑时表现得像个”书呆子”,无法给出稳定的游戏策略。
Real-World Experience
- 配置与部署:所有模型在面对复杂 Web 工程时,都无法做到真正的”开箱即用”。o4 mini high 的表现最令人沮丧,因为其生成的配置文件包含大量虚构信息。
- 日常使用感:o3 在处理 Python 脚本(如 Pygame)时非常顺滑,一次性成功率高。Gemini 2.0 Pro 虽然需要少量人工干预,但其推理思路清晰,能解释版本差异的原因。
- 意外之喜:Gemini 在实现”AI 自动玩游戏”时的可视化逻辑(画出边界线和轨迹线)非常直观且稳健,体现了极强的多模态理解力。
Who Should Buy This?
- 竞赛选手/科研人员:首选 o4 mini high。其处理数学难题和算法竞赛题目的能力远超同类模型,是突破逻辑瓶颈的神器。
- Python 开发者/游戏原型制作:首选 o3。它在逻辑相对闭环的单文件工程中表现最稳定,代码一次性运行率高。
Who Should Skip This?
- 追求极致性价比的个人开发者:建议避开 o3/o4 的高额成本,直奔 Gemini 2.0 Pro。Gemini 提供了非常慷慨的免费额度(Web 端与 API),且综合工程能力与 o3 互有胜负,是目前最香的生产力工具。 [00:25:03]
Visual Evidence
Screenshots captured from the video at key moments:
对比图
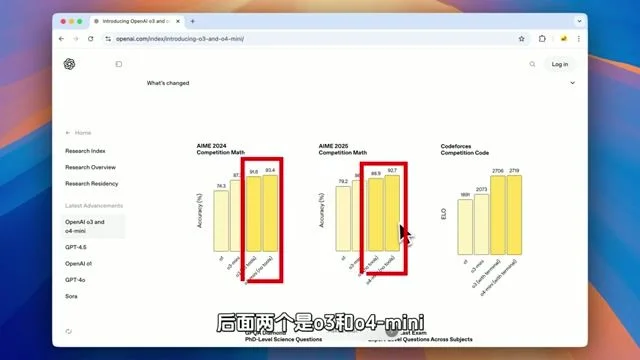
Captured at [00:27] — 展示官方给出的数学和编程能力提升数据,作为评测背景。
测试的结果

Captured at [03:12] — 这是本文的核心数据点,直观展示 o4 mini high 在算法上的压倒性优势。
修复后的版本
Captured at [06:16] — 展示 Gemini 在工程实现上的初始效果及其 UI 局限性。
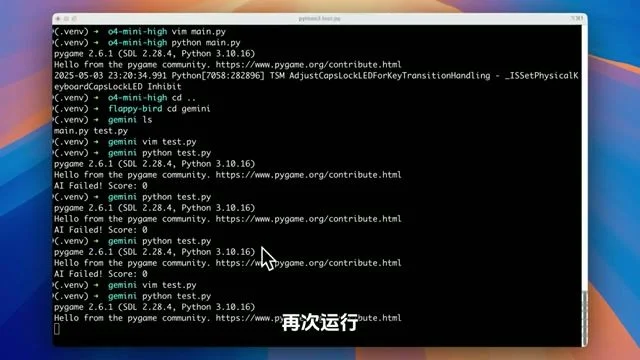
很糟糕
Captured at [13:35] — 展示模型在多次迭代后可能出现的”负优化”和项目崩溃现象。
三条线
Captured at [19:11] — 展示模型在处理复杂物理模拟和策略生成时的逻辑深度。
画了一张图
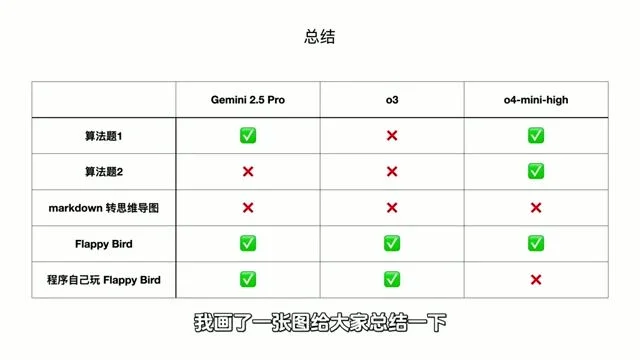
Captured at [22:31] — 视频结尾的总结图表,适合作为文章的总结性视觉元素。