AI 核心概念与技术深度解析 2026年1月15日
Token 到底是什么?—— 揭秘大模型背后的'文字压缩术'
深入理解大模型处理信息的基本单位 Token,掌握 Context Window 的真实容量换算,以及 BPE 算法如何提升模型效率。
#大模型
#Token
#Tokenizer
#BPE算法
#人工智能
Quick Verdict
Token 是大模型处理信息的基本单位,它是人类文字与模型数字世界之间的”翻译官”。理解 Token 不仅能帮你搞清楚 Context Window 的真实容量(如 40 万 Token 并不等于 40 万字),还能揭示大模型如何通过压缩技术提升处理效率。简而言之,Token 是大模型运行的燃料,其质量和数量直接决定了 AI 的理解力与响应成本。
Key Decision Factors for AI Model Evaluation
- Context Window 容量:决定了模型一次能”记住”并处理的信息上限。
- 分词器 (Tokenizer) 压缩比:同等 Token 数量下,压缩比越高,模型处理的实际文字量越大。
- 算法类型:OpenAI 偏好的 BPE 与 Google 偏好的 Unigram 在分词逻辑上各有侧重,影响多语言处理能力。
- 推理效率:Token 数量越少,模型推理速度越快,成本越低。
Specs & Benchmarks
| Specification | Value | Context/Notes |
|---|---|---|
| GPT-5.2 Context Window (示例) | 400,000 Tokens | 视频中用于举例的最大处理量 |
| 中文换算比例 | 1 Token ≈ 1.5 - 2 个汉字 | 大模型处理中文的平均效率 |
| 英文换算比例 (字母) | 1 Token ≈ 4 个英文字母 | 英文分词的细粒度标准 |
| 英文换算比例 (单词) | 1 Token ≈ 0.75 个单词 | 英文语境下的通用换算系数 |
| 400k Token 实测容量 (中文) | 60 - 80 万汉字 | 考虑压缩比后的实际文本承载量 |
| 400k Token 实测容量 (英文) | 约 30 万单词 | 考虑压缩比后的实际文本承载量 |
The Ugly Truth
- Token ID 无语义:[00:04:18] 很多人误以为 Token ID 像 Embedding 向量一样有语义关联,但实际上它只是一个纯粹的编号,并不包含任何词义信息。
- 单字效率陷阱:[00:05:12] 如果 Tokenizer 训练不佳或词表太小,会导致大量文本被切分为单字 Token,极大地浪费 Context Window 并拖慢推理速度。
- 非等比例换算:Token 与字/词并非 1:1 关系,初学者极易在评估 API 成本和输入长度时产生误判。
Real-World Experience
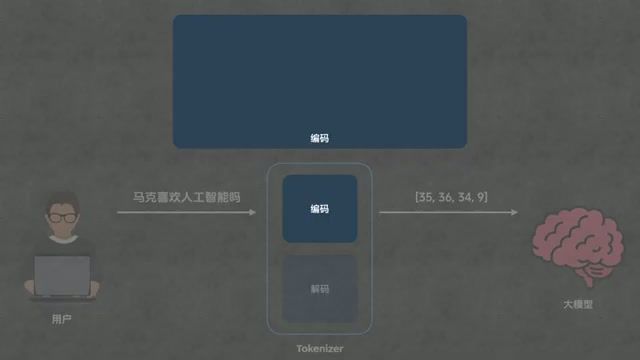
- Tokenizer 的角色:它像是一个翻译官加压缩机。在编码阶段,它将文字”切分”并”映射”为数字(Token ID);在解码阶段,将模型吐出的数字转回文字。
- 训练逻辑:Tokenizer 是通过算法(如 BPE)从海量文本中”找规律”训练出来的。它会统计高频组合(如”智”+“能”=“智能”),并将其固化为一个 Token,从而实现数据压缩。
- 性能优化:通过合并高频词汇,Tokenizer 能将原本 9 个字的句子压缩为 4 个 Token [00:09:50],这直接提升了模型的推理效率。
Who Should Buy Into This Concept?
- AI 开发者:需要优化 Prompt 长度并精确计算 API 调用成本的专业人士。
- 企业决策者:在对比不同模型(如 GPT-4 vs Claude)的 Context Window 参数时,需要具备真实容量换算能力的管理者。
- 技术爱好者:希望从底层逻辑理解大模型运行原理的深度学习初学者。
Who Should Skip This?
- 仅偶尔使用对话界面的普通用户:如果你不关心 API 计费或长文本处理上限,仅关注输出结果,可以暂不深究 Token 细节。
Visual Evidence
Screenshots captured from the video at key moments:
Tokenizer
Captured at [00:53] — 展示 Tokenizer 在人类文字与模型数字之间的桥梁作用
切分

Captured at [01:30] — 演示文字如何被切分为 Token 并转换为 Token ID 的具体步骤
Bpe

Captured at [03:25] — 对比不同科技巨头采用的主流分词算法
合并
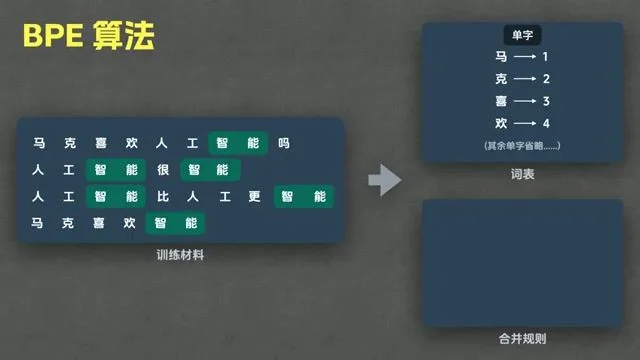
Captured at [06:00] — 可视化展示高频词组如何合并成单个 Token 的过程
换算
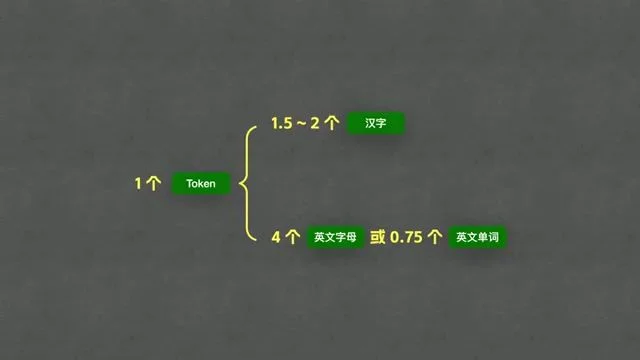
Captured at [10:07] — 为读者提供实用的 Context Window 换算参考数据